본 게시물은 LG aimer 커리큘럼에 수록된 주재걸 교수님의 강의 자료를 포함하고 있습니다.
안녕하세요.😊 이번 게시글은 transformer를 사용한 모델 중 널리 알려진 Bert를 이해해보겠습니다.
What is self-supervised learning?
Bert를 설명하기에 앞서 자기 지도학습에 대해 설명하겠습니다.
self-supervised learning, 자기지도 학습이란 unlablded data가 주어졌을 때 input x 내에서 target으로 쓰일만 한 것을 정해서, 즉 self로 task를 정해서 supervision 방식으로 학습하는 것을 말합니다. pre-task를 학습한 모델은 down stream tast에 transfer해서 사용할 수 있습니다. 따라서 데이터 및 연산이 많이 필요한 pre-trained model은 대형 업체에서 미리 만들고 deep learning을 모르는 사용자가 이를 활용해 간단한 조작으로 fine-tuning하여 자신의 task에 적합한 model을 만들 수 있습니다. 이러한 자기지도 학습은 tagged data 수집의 어려움으로 등장했습니다.
Transfer learning from self-supervised pre-trained model

특정한 self-supervised learning을 사용한 사전 학습은 fine-tuning을 통해 자신이 해결하는 task의 정확도를 높여줄 수 있습니다. Input A 단계에서 앞쪽 Frozen layer에서는 유의미한 패턴을 추출하도록 학습되는데 이는 다른 여러 task에도 적용 가능해야 합니다. 이후 Backprop 단계에서는 직접적으로 주어진 task를 해결하도록 학습하게 됩니다. 이렇게 되면 Input B 상황에서 사전에 학습한 Frozen layer는 추가적으로 새롭게 학습할 필요 없이 새로운 task인 부분만 Backprop하면 됩니다. 이를 통해 많은 시간과 비용을 절약할 수 있습니다.
BERT
대규모 data를 통한 self-supervised learning과 사전 학습된 모델을 통해 다양한 target task에 적용해서 성능을 높이는 사례들은 자연어 처리에서 많은 발전을 이루었습니다. Self-supervised learning model 중 대표적인 model이라고 할 수 있는 Bert에 대해 알아봅시다!

Bert 논문의 제목에는 pre-training이라는 단어가 포함되어 있습니다. Bert는 사전 학습 모델의 한 종류로 다양한 task에 적용하기 전에 두 가지 사전 학습을 하게 됩니다. 또한 transformer 구조를 사용해 양방향 학습을 진행합니다. Bert의 학습 과정은 unlabeld된 데이터를 입력한 후 여러 embedding 과정을 거쳐 필요한 정보를 잘 encoding한 hidden state vector를 단어 별로 만드는 것입니다.
Pre-training task of BERT
BERT의 사전 학습에 설명하겠습니다.
Masked language modeling((MLM))

Maksed language modeling은 대용량의 text data를 학습할 때 self-supervised learning을 위해 mask라는 특별한 token을 사용하고 masked 단어를 맞추는 학습을 하는 것을 말합니다. 그림에서 Sentence A가 입력 되었을 때 중간 단어를 masking하는 것을 볼 수 있습니다. 단어를 masking할 때는 전체 문장 중 15%의 랜덤한 단어를 masking합니다. 이 때 masking 되지 않은 다른 token을 encoding할 때 모델이 게을러지는 것을 방지하기 위한 몇 가지 trick을 사용합니다.

- 15%의 단어 중 80%의 단어만 [MASK]토큰으로 masking합니다.
- 나머지 10% 단어는 다른 random한 단어로 대체 합니다.
- random하게 다른 단어로 대체된 단어를 encoding한 hidden state vector를 가지고 그 자리에 들어갈 단어가 무엇인지 예측하도록 했을 때는 다른 단어들도 최대한 유용한 정보를 잘 encoding 하도록 모델이 학습될 것입니다.
- 나머지 10% 단어는 기존 단어를 유지하고 기존 단어를 예측합니다.
BERT model이 문제 출제 비율을 15%로 설정한 이유는 다음과 같습니다.
- masking이 너무 적을 경우: 많은 비용으로 encoding 했는데 문제가 적으면 비효율적일 것입니다.
- masking이 너무 많은 경우: 많은 단어를 masking하면 문제를 푸는데 필요한 정보가 절대적으로 부족할 것입니다.
Next Sentence Prediction((NSP))

Next sentence predictiond은 여러 문장이 입력으로 주어졌을 때 BERT 모델을 fine-tuning해서 사용할 수 있도록 사전 학습 단계에서 두 개의 문장이 하나의 문서 상에서 연속적으로 등장할 수 있는 문장인지 판단하는 학습을 말합니다. 그림 2 Sentence A 앞에 있는 입력 sequence token인 CLS token을 NSP ouput layer에 입력으로 줘서 binary classificaiton을 수행합니다. CLS token은 두 문장이 next sentence인지 아닌지 판단하는데 사용하는 정보들을 주어진 입력 sequence 내에 있는 단어들로부터 self-attention module을 통해 추출합니다. 그림 5에서 볼 수 있듯이 서로 관련된 문장이면 'IsNext', 관련없는 문장이면 'NotNext'로 분류합니다.
Segment Embedding and position embedding

BERT model은 transfomer를 사용했지만 embedding 단계에서 차이점이 있습니다. 바로 segment embedding이 추가되었다는 것입니다. BERT는 NSP도 학습을 해야하기 때문에 문장과 관련된 embedding을 추가적으로 해줘야합니다. 따라서 Transformer의 positional encoding 달리 특정한 단어가 몇 번째에 나타났는가에 대한 정보를 추가하는 position embeddings 뿐만 아니라 단어가 어떤 문장에 속하는지와 관련된 정보가 있는 segment embedding을 추가적으로 수행합니다.
Various fine-tuning approaches
하나의 텍스트에 대한 텍스트 분류 유형

BERT를 사용하는 첫 번째 유형은 하나의 문서에 대한 텍스트 분류 유형입니다. 이 유형은 영화 리뷰 감성 분류, 로이터 감성 분류 등과 같이 입력된 문서에 대해 분류를 하는 유형으로 문서의 시작에 [CLS]라는 token을 입력합니다. [CLS] token은 BERT가 분류 문제를 풀기 위한 특별한 token으로 사용됩니다. 텍스트 분류 문제를 풀기 위해서 [CLS] token의 위치의 출력층에서 밀집층(Dense layer) 또는 같은 이름으로 완전 연결층(Fully connected layer)를 추가하여 분류에 대한 예측을 합니다.
하나의 텍스트에 대한 태킹 작업
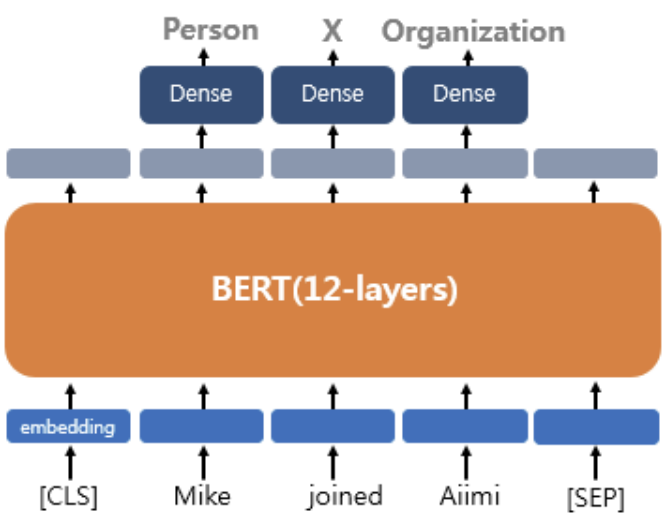
BERT를 사용하는 두 번째 작업은 tagging 작업입니다. RNN 계열의 신경망을 이용해서 풀었던 task입니다. 대표적으로 문장의 각 단어에 품사를 tagging하는 품사 tagging 작업과 개체를 tagging하는 개체명 tagging 인식 작업이 있습니다. 출력층에서는 각 입력 text의 각 token의 위치에 밀집층을 사용하여 분류에 대한 예측을 합니다.
텍스트의 쌍에 대한 분류 또는 회귀 문제

BERT는 텍스트의 쌍으로 입력 받는 task도 풀 수 있습니다. 대표적인 task로 자연어 추론(natural language inference)가 있습니다. 자연어 추론 문제란 두 문장이 주어졌을 때 하나의 문장이 다른 문장과 논리적으로 어떤 관계에 있는지 분류하는 것입니다. 유형으로는 모순 관계(contradiction), 함의 관계(entailment), 중립 관계(neutral)가 있습니다.
text의 쌍을 입력받는 경우 입력 text가 하나가 아니므로 텍스트 사이에 [SEP] token을 집어넣고, Sentence A embedding과 Sentence 1 embedding이라는 두 종류의 segment embedding을 모두 사용하여 구분합니다.
질의 응답

Text의 쌍으로 입력 받는 다른 task로 question answering이 있습니다. BERT로 QA를 풀기위해서는 질문과 분문이라는 두 개의 text 쌍을 입력합니다. 이 task를 푸는 방법은 질문과 본문을 입력 받으면, 본문의 일부분을 출력해서 질문에 답변하는 것입니다. 다음 한국어 예시를 들어보겠습니다. "강우가 떨어지도록 영향을 주는 것은?" 라는 질문이 주어지고, "기상학에서 강우는 대기 수증기가 응결되어 중력의 영향을 받고 떨어지는 것을 의미합니다. 강우의 주요 형태는 이슬비, 비, 진눈깨비, 눈, 싸락눈 및 우박이 있습니다." 라는 본문이 주어졌다고 해보겠습니다 이 경우, 정답은 "중력"이 되어야 합니다.
이상으로 BERT 모델의 구조를 간략히 살펴보았습니다. BERT는 transformer를 활용한 대표적인 pre-training model입니다. 해당 게시글의 목적은 BERT model의 구조의 특징을 살펴보는 것으로 자세한 수식을 넣지는 않았습니다.
Self-supervised learning
https://lifeisenjoyable.tistory.com/15
Self-supervised learning (자기지도 학습) 이란?
요즘 Deep learning에서 주목받고 있는 학습법인 Self-supervised learning을 소개할까 합니다. 이번 글에서는 Self-supervised learning에 대한 간단한 소개 이후 왜 이 학습법이 주목받는지, Self-supervised learning
lifeisenjoyable.tistory.com
BERT
https://moondol-ai.tistory.com/463
버트(BERT) 개념 간단히 이해하기
본 글은 "딥 러닝을 이용한 자연어 처리 입문"을 학습하며 작성한 것입니다. 중간중간 제가 이해한 내용을 좀 더 풀어서 썼습니다. 문제가 된다면 비공개 처리하겠습니다. 버트(BERT) 개념 BERT(Bidir
moondol-ai.tistory.com
'AI' 카테고리의 다른 글
| Beyond efficient transformer for long sequence time-series forecasting (0) | 2023.02.27 |
|---|---|
| A Transformer-based Framework for Multivariate Time Series Representation Learning (0) | 2023.02.13 |
| Time-series Transformer: Transformer를 사용한 다변량 시계열 데이터 예측 (0) | 2023.01.25 |
| Transformer: Attention is all you need (0) | 2023.01.18 |
| Seq2Seq and Attention model (0) | 2023.01.18 |