본 게시물은 LG aimer 커리큘럼에 수록된 주재걸 교수님의 강의 자료를 포함하고 있습니다.
안녕하세요!😊 오늘은 제가 가장 관심있는 연구 분야인 시계열 예측과 관련된 방법론에 대해 적어보겠습니다. 이번 게시글은 Transformer를 다변량 시계열 데이터에 최초로 적용한 논문 리뷰입니다.
논문의 제목은 'A transformer based framework for multi variate time series representation learning.'입니다.
해당 논문의 특징은 다음과 같습니다.
- Transformer의 encoder 구조만 사용
- pre-training task를 위하여 연속적인 길이의 input masking을 사용
- layer normalization 대신 batch normalization 사용
- fine-tuning 단계에서 구조를 어떻게 설계하느냐에 다라 classification, regression, forecasting, missing value imputation 등 다양한 task에 적용 가능합니다.
Sequential Data
본격적인 설명에 앞서 sequential data에 대해 설명하겠습니다.

위 그림은 non-sequential data를 설명하는 자료입니다. Non-sequential data란 시간 정보를 포함하지 않고 생성되는 데이터입니다. 순차 데이터가 아닌 경우 데이터는 N by D 행렬(N:관측치 수, D: 변수 수)로 표현됩니다.
- 예) 특정 고객의 금융상품 이용 현황을 바탕으로 대출 상품 추천
- X: 고객별 금융 상품 이용 현황
- Y: 대출 상품 이용 유무 (1: 사용, 0: 미사용)

반면 sequential data는 시간 정보를 포함하여 순차적으로 생성되는 데이터 입니다. 순차 데이터의 경우 데이터는 (N) by T by D Tensor (T는 측정 시점 수)로 표현됩니다. 그림 2처럼 N개의 T차원 시점 vector를 가지게 되고, D 차우너의 변수의 크기를 갖게 됩니다.
Type of time series task
이제 시계열 예측 문제의 유형에 대해 설명하겠습니다.

다음과 같은 time series data가 존재한다고 가정하겠습니다. 모든 변수는 동일한 주기(초, 분, 시간 등)로 수집되고 있습니다. 이 때 다음과 같은 model들을 만들 수 있습니다. 위와 같은 X를 사용하면 task 1의 Y 값은 1 or 0으로 출력될 것이고, task 2의 Y 값은 특정한 수치 값으로 출력될 것입니다.
- Task 1-Classification: 특정 기간(제품 가공 기간) 데이터를 입력으로 하고 특정 범주를 출력으로 하는 분류 모델 (제품의 양/불 판정 등)
- Task 2-Regression: 특정 기간 데이터를 입력하고 특정 수치(품질 지표)를 출력으로 하는 회귀 모델

- Task 3-Regression: 일부 기간 데이터를 입력으로 하여 이후 기간 데이터를 예측하는 회귀 모델

- Task 4-Anomaly Detection: 일부 기간 데이터를 입력으로 하여 행당 상황의 정상/비정상 여부를 탐지하는 모델
Time series transformer: TST 작동 원리

TST는 크게 Pre-training과 Fine-tuning의 2 Phases로 구분됩니다. Pre-training은 transformer의 구조를 미리 학습하는 것으로 생각하면 되고, Fine-tuning은 문제를 잘 풀 수 있게 고도화하는 것으로 생각하시면 됩니다.
입력 데이터 변환

원본 입력 데이터 X는 m개의 변수와 w개의 time window length를 가집니다. Pre-training 과정에서는 이 중 일부를 masking한 뒤 transformer의 input이 되는 d차원(d<m)으로 변환합니다. 변환되는 차원의 크기는 학습을 통해 최적화됩니다.

Fine tuning 과정에서는 Masking 없이 d차원으로 변환합니다. 해결해야 하는 task에 필요한 새로운 data는 masking을 해서 맞출 필요가 없습니다. Pre-training 단계에서 transformer는 유사한 데이터를 통해 충분히 학습했기 때문입니다.
입력 데이터 Masking

Transformer의 사전 학습 목적은 Masking된 부분을 정확하게 예측하는 것으로 설계됩니다. 이 때 각 cell에 대한 masking 여부를 독립적으로 결정하게 되면 Trivial solution으로도 문제를 잘 맞추는 상황이 발생합니다.
- Trivial solution: Masking된 cell의 이전 시점 혹은 이후 시점 값을 그대로 사용하거나 양쪽 cell의 평균 값을 사용하는 방법
따라서 Masking의 길이가 평균 $l_m$만큼 되는 기하분포를 따르도록 Markov Chain을 적용하여 masking 여부를 결정합니다. 이 말은 masking을 연속적으로 하도록 유도했다고 생각하시면 됩니다. 그림 9에서 block이 세로로 길게 칠해져 있는 것을 볼 수 있듯이 한 시점 앞뒤로 연속적 masking이 된 것을 확인할 수 있습니다.
- 이 때, 모든 변수에 대해 동일한 시점을 masking하는 것보다 변수별로 독립적으로 masking segment를 결정하는 것이 실험적으로 더 우수한 성능을 나타냅니다. 그림 9에서 block들의 칠해진 길이가 서로 다른 것은 위와 같은 이유 때문입니다.
Position encoding

NLP에서의 transformer와 마찬가지로 TST에서도 입력 데이터에 postion encoding을 더해서 transformer encoder의 입력 값으로 사용합니다. 고정된 postion encoding을 사용할 수도 있고, 학습 가능한 postion encoding을 사용할 수도 있습니다.
Self-attention in transformer encoder block

TST는 transformer model의 encoder만을 사용했습니다. 하지만 기존 transfomer와 다른 점은 총 3개의 encoder block을 사용했다는 점입니다. 기존 transformer model은 6개의 encoder block을 사용했지만 실험 상 큰 효과가 없어 본 논문에서는 3개의 encoder block을 사용했습니다. 또한 NLP에서의 Transformer와 다르게 Layer normalization 대신 batch normalization을 사용했습니다. 그 이유는 다음과 같습니다.
- 시계열 데이터에는 NLP word embedding에는 없는 이상치가 존재합니다.
- 시계열 데이터는 각 관측치의 길이 변화가 NLP의 문장 길이 변화보다 작습니다.
위와 같은 상황에서 실험적으로 batch normalization이 layer normalization보다 성능이 우수한 것으로 입증되었습니다.
Pre-training

사전 학습 관점에서 우리가 해야할 것은 독립적으로 생성한 masking에 대해서 encoder에 적용시킨 후 FeedForward Neural Net을 통해서 훼손시킨 원본 데이터를 맞추는 것입니다. Masking된 부분의 실제 값과 예측 값의 mean squared error를 기반으로 모델을 학습합니다.
Fine-tuning

다음은 fine tuning 단계입니다. Fine-tuning 단계에서는 잘 학습된 데이터를 가지고 전체 sequence에 대해서 각각의 time 시점 별로 data의 vector를 이어붙입니다. 이 부분을 concatenation으로 설명하고 있습니다. 또한 해당 논문에서는 fine-tuning task를 수행하기 위한 output layer를 제외한 pretrained model은 freezing하고 fine-tuning을 진행합니다.
- Masking을 적용하지 않은 input time window를 input encoding과 transformer encoder에 순차적으로 넣어 representation을 도출합니다.
- 도출된 모든 시점의 representation을 concatenation한 것을 output linear layer에 input으로 넣어 regression 또는 classification의 정답을 예측합니다.
- task의 실제 정답과 TST가 예측한 값의 차이를 통해 output linear layer를 fine-tuning합니다.'
성능
Q1. Given partially labeled dataset of a certain size, how will additional labels affect performance?
주어진 특정 사이즈에 레이블이 존재하는 데이터에서 추가적으로 label이 주어졌을 때 얼마만큼 더 효과를 얻을 것이냐?
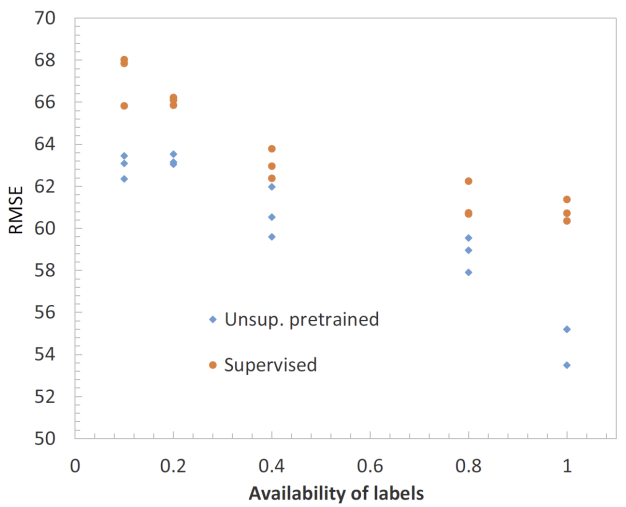
Supervised learning에 사용되는 label의 비율 증가에 따른 TST(pretrained)와 TST(sup.only)의 성능 변화를 통해 아래의 결과를 확인할 수 있습니다.
- 두 모델 모두 사용 가능한 label의 비율이 증가할수록 성능이 향상됩니다.
- TST(pretrained)가 TST(sup.only)보다 모든 비율에서 높은 성능을 도출한 것을 통해 동일한 training set을 중복 사용하여 모델을 학습한 것이 효과가 있다는 것을 알 수 있습니다.
Q2. Given labeled dataset, how will additional unlabeled samples affect performance?
labeled data를 고정해놓고, label이 없는 data를 얼마만큼 많이 썼을 때 효과가 있는가?

Fine-tuning data의 개수가 고정되었을 때, pre-training에 사용되는 데이터의 비율 증가에 따른 TST(pretrained)의 성능 변화를 통해 아래 결과를 확인할 수 있습니다.
- Pre-training에서 많은 데이터를 학습할수록 TST(pretrained)의 성능이 향상됩니다.
- TST(pretrained)의 fine-tuning 데이터의 개수가 적을수록 pre-training에 사용되는 데이터의 비율 증가에 따른 성능 향상 폭이 큽니다.
이상으로 Time series Transformer에 대해 간략히 알아보았습니다. 저도 제 연구 분야와 관련 깊은 만큼 앞으로 계속 공부해나갈 예정입니다.
'AI' 카테고리의 다른 글
| Beyond efficient transformer for long sequence time-series forecasting (0) | 2023.02.27 |
|---|---|
| A Transformer-based Framework for Multivariate Time Series Representation Learning (0) | 2023.02.13 |
| Bert: Pre-training of deep bidirectional transformers for language understanding (0) | 2023.01.25 |
| Transformer: Attention is all you need (0) | 2023.01.18 |
| Seq2Seq and Attention model (0) | 2023.01.18 |